Deployment models
A range of models using a number of different components can be deployed, depending on the scale and use cases of the organisation deploying a terminology solution.
Typically the selection of the model will revolve around requirements relating to:
- Content authoring
- Control of the content authoring process
- Control of the release/publication process
- Production runtime use of published content.
The different deployment models have substantial impacts on the overall release process, and dictate the gates available in the process as well as affecting the details of the process.
Key factors discussed over the remainder of this section include
- Whether a separate read-only production endpoint is being used to separate content use from content development
- Whether a staging endpoint is being used to test publications
- And whether a syndication server is being used to store release states.
Common deployment models
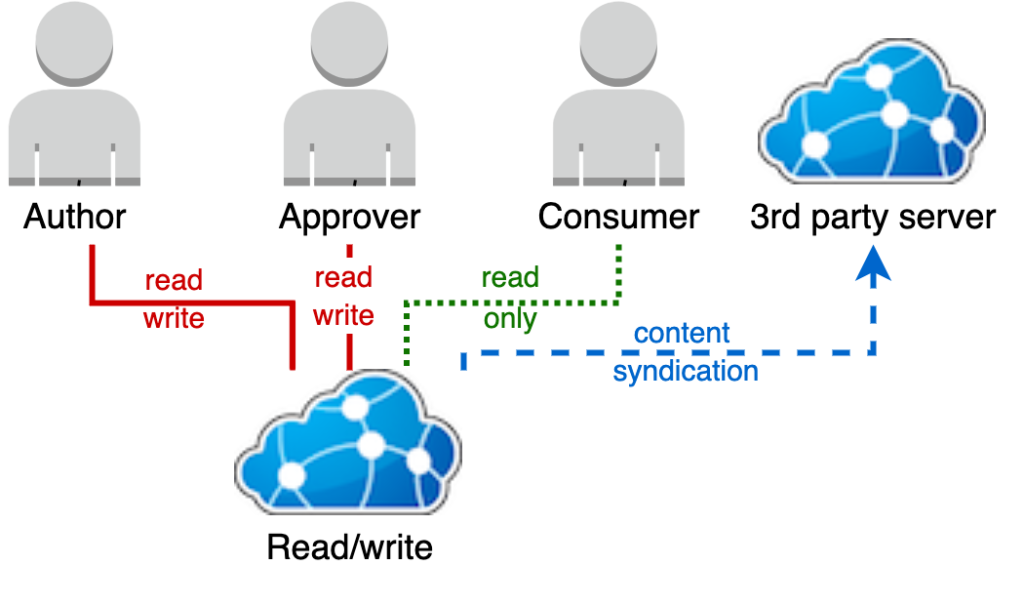
Single read/write terminology model
This is the simplest option, where content is authored and used from the same single read/write terminology server endpoint.
As there is no separate endpoint for content use, control of the visibility of content for consumers must be entirely driven by the resource-level security model of Ontoserver using FHIR security labels.
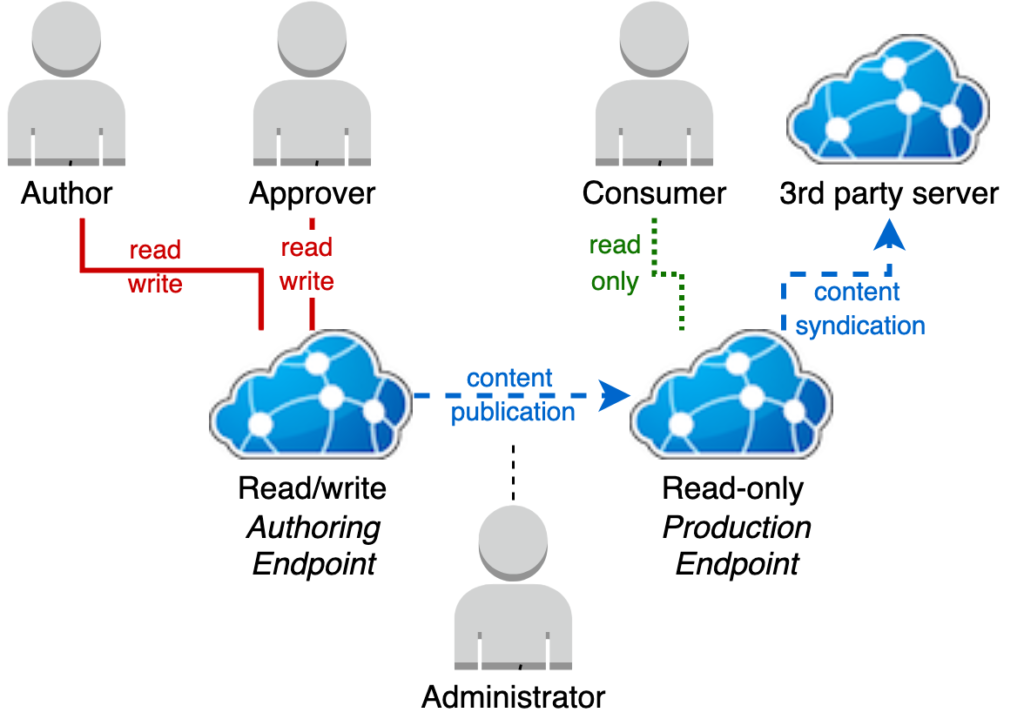
Separate authoring and production servers
Separating out a production endpoint allows control over when content under development is exposed to consumers. It also allows different infrastructure for performance and availability to be used for content development versus content use.
Adding a read-only endpoint allows for separation of content development and content use across two separate endpoints.
A read/write server is used to develop content, while a read-only server is used to consume content. This provides a gap where extra control can be exerted over the approval and release process.
This model can be used to perform releases to the production endpoint when a milestone state has been achieved on the Authoring server, or operate a continuous delivery model by configuring the read-only Production server to pull new content from the Authoring server’s syndication feed on a schedule.
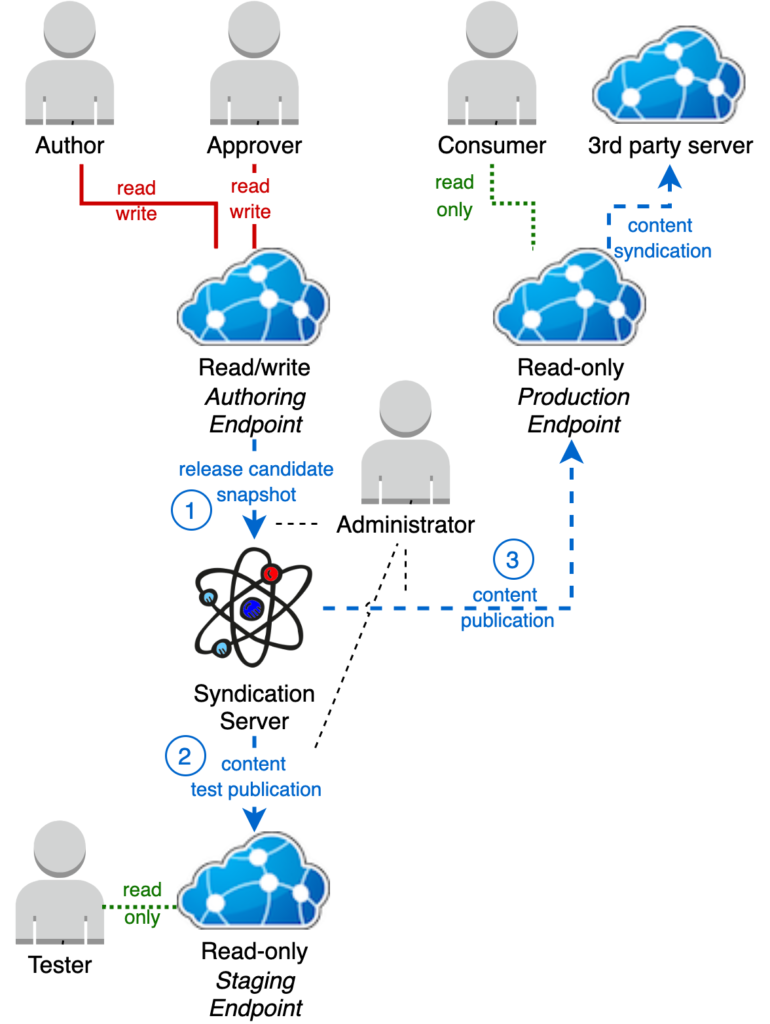
Staging and syndication server
The most comprehensive solution is to use both a Staging server and a syndication server. This allows for full release history, rollbacks to any previous release point and production-like testing of release candidates prior to production publication.
Under this model, authors develop content on the Authoring terminology server. Content is approved by users with an Approver role using the Approval processes, which changes the state of the Authoring server’s syndication feed to include or omit the resource depending upon the approver’s decision.
When the syndication feed of the Authoring server achieves a milestone publishable state, an Administrator creates a release candidate snapshot (1) of the Authoring server’s syndication feed in the syndication server. This is a static snapshot of the Authoring syndication feed which can then be deployed to the Staging server (2) for testing and verification.
If testing passes, the release candidate snapshot feed in the syndication server can be deployed to the Production terminology server (3) by an Administrator making the content available for downstream consumers on the FHIR and Syndication APIs. If testing fails, corrections need to be made on the Authoring server and the process re-executed.
As multiple release candidates are created over time, a process is also described in the following sections to list the available release candidate snapshots on the syndication server to aid Administrators.