Horizontally scaled read-only endpoint
Both Ontoserver and Ontocloak can be horizontally scaled using a cluster of instances that support a single, logical endpoint.
This is typically done to:
- Scale up and down instances based on load to provide high performance;
- Provide high availability.
Both Ontoserver and Ontocloak require that the instances supporting the endpoint sit behind a load balancer which routes and balances incoming requests across the available instances.
Atomio, given its usage pattern and availability requirements, does not provide this capability.
Ontoserver
Ontoserver supports the operation of multiple instances in support of a single endpoint for horizontal scaling and/or high availability.
There are a number of requirements when creating a cluster of Ontoserver instances, described in following sections. The basic deployment strategy is to use multiple Ontoserver worker instances using the same data and software version (to ensure all instances respond equally to requests) with a load balancer in front of the instances to route requests.
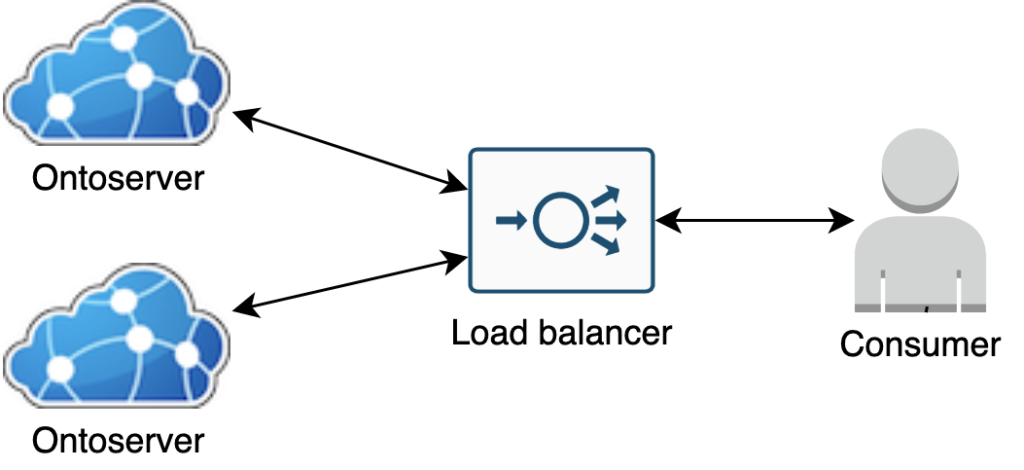
Multiple Ontoserver instances behind a load balancer
Multiple instances of Ontoserver can be used to support a read-only endpoint to support high/variable performance demands, and/or to ensure high availability. Read-only endpoints can be integrated with applications to support run-time use, and to service time-critical and operationally-critical requests.
While booting an Ontoserver container after loss (for example the loss of the Docker node hosting it) can be automated, and the couple of minutes this takes is very often more than tolerable, this may be too slow for some extreme settings. Similarly, simply provisioning appropriate CPU and memory resources to a single Ontoserver instance is very often sufficient to meet performance requirements. However there may be some extreme cases where exceptionally high or variable loads with critical response times cannot be resolved by simply increasing CPU and memory resources to a single Ontoserver instance.
If one (or both) of these is truly required, the cost and complexity of a multiple Ontoserver instance cluster supporting the endpoint may be justified – particularly where tight SLAs are in place.
Shared versus separate disk storage and database
When operating multiple instances of Ontoserver to support an endpoint, decisions must be made about how the storage and database infrastructure will be provisioned to support these instances. Specifically, a decision will need to be made regarding whether each instance will have its own separate private resources, or whether the resources will be shared between the instances.
The table below specifies the supported and unsupported operating modes for an Ontoserver scaled instance (multiple instances supporting an endpoint) with regard to shared/separate disk and database.
| Database | Disk | Status |
|---|---|---|
| Shared | Separate | Supported (best) |
| Separate | Separate | Supported (legacy) |
| Shared | Shared | Not Supported (deprecated) |
| Separate | Shared | Not supported |
Note: While a read-only endpoint may use separate disk and databases for each instances, this has implications for where the conceptual source-of-truth for the terminology service’s state lives. In the case of non-shared disk/database, the preload feed is the source of truth. In the (deprecated) case of shared disk/database, the database itself would be the source of truth.
Shared database, separate disk
This is the absolutely preferred deployment model for horizontal scaling because the Ontoserver instances auto-discover each other and coordinate themselves to manage the complexities of FHIR’s stateful interactions and content updates via syndication and preload feeds. (Currently this is managed using Infinispan.)
This mode is enabled by setting the configuration parameter:
ontoserver.deployment.scaled=truethis also implies (forces)
ontoserver.deployment.readOnly=trueThe deployment then consists of
- A shared PostgreSQL instance, typically using the cloud platform service since this simplifies backups and availability.
- Each Ontoserver container using its own local container storage on the Docker host, ideally SSD to maximise performance.

In this readonly mode, Ontoserver ensures that no FHIR update operations can be performed (regardless of the security model and associated permissions in the token). The only only way to load / update content on the instances is via the preload and syndication feed(s).
Note that for SNOMED CT and LOINC, the associated content MUST remain available in these feeds so that newly started instances are able to load their indexes.
Separate disk and database (legacy)
Typically this is achieved using:
- A PostgreSQL container deployed alongside each Ontoserver container, typically using local container storage, ideally on the same host to minimise latency
- Each Ontoserver container using its own local container storage on the Docker host, ideally SSD to maximise performance.
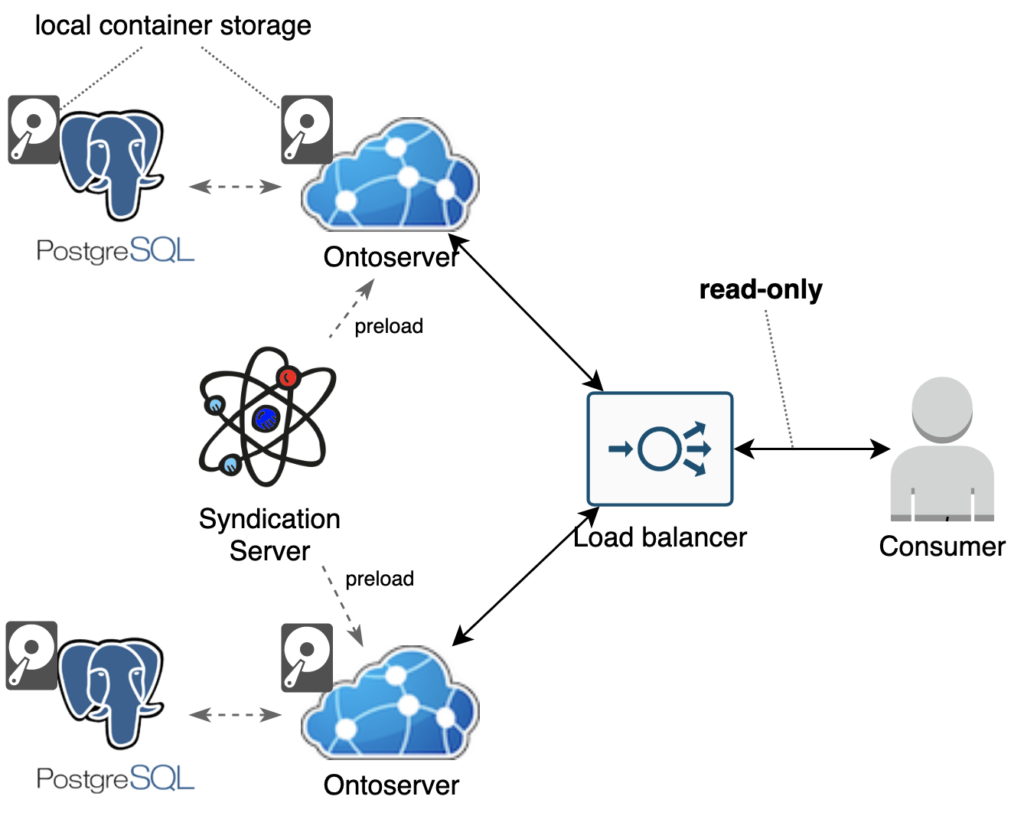
This method uses entirely transient storage for the containers, and relies upon Ontoserver instances being able to rebuild their disk and database state upon boot from their configured preload syndication feed. This method uses the read-only nature of the endpoint to remove the need to synchronise state due to write operations for each Ontoserver instance – state is synchronised to the configured common preload syndication feed.
Shared disk and database — deprecated
Typically this is achieved using:
a shared filesystem technology like NFS or SMB which can be mounted in a read/write mode by multiple Docker containers concurrentlya central PostgreSQL database with a single schema all Ontoserver instances connect to.
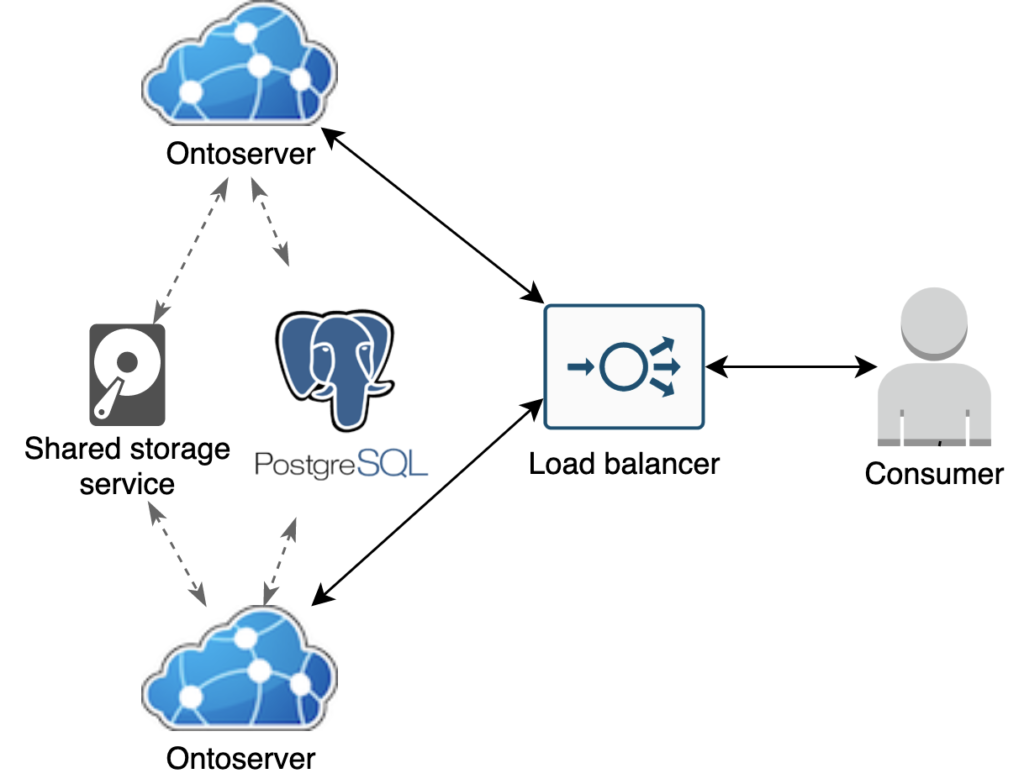
This infrastructure cannot match low latency disk access when using instance storage on the Docker node hosting the Ontoserver container. Similarly with co-located twinned Ontoserver and PostgreSQL containers, centralised databases introduce latency to the overall solution, which has a further performance cost.
Therefore, a performance hit compared to separate instance storage and separate databases co-located with each Ontoserver container is likely. This can be minimised with premium storage infrastructure, however is unlikely to be able to match local storage on the Docker host if it is SSD.
Note: When shared disk and database are being used for such a read-only endpoint with a preload feed, a single Ontoserver instance should be started and allowed to complete the preload process prior to the other Ontoserver instances being started. This prevents multiple Ontoserver instances attempting to load data from the preload feed onto shared disk and database concurrently which will likely result in numerous error messages in their log files.
Stateful requests
The $closure FHIR operation creates and relies on in-memory state in the server that cannot be replicated in a scaling solution. To address this, these requests should be sent to the same server. This can be done either using stateful/stateless servers, or sticky sessions. We feel that the former is preferable, unless specific expected usage patterns indicate otherwise.
Stateful/stateless servers
This model allocates one server as the stateful server, and the ingress controller/load balancer is configured to redirect all stateful requests to that server. The advantage of this is that these requests can be shared across multiple clients, e.g. multiple clients can use/maintain a shared closure table. The disadvantage is that the endpoint does not scale horizontally for these types of requests (these are not typically the requests that lead to a requirement for scaling).
Sticky sessions
The sticky sessions model relies on the ingress controller/load balancer directing all requests from a given client (based on source IP and/or HTTP referrer header) to the same server. This allows the endpoint to scale horizontally for these requests. However, it is not possible for different clients to share a closure table.
Ontoserver does not provide any application level support for sticky sessions, and is not able to set headers or cookies for the purpose of creating hints for a load balancer to manage sticky sessions.
Content and software deployments
Logically, to ensure consistent behaviour of an endpoint across requests for clients, at any given moment the active Ontoserver instances serving the endpoint must be operating on the same software version and content.
Synchronising content
Using shared disk and database across Ontoserver instances achieves synchronisation of data across the instances. Even in the face of different configuration of preload/syndication feeds for different instances (not recommended), the state being served by all Ontoserver instances will be the content of the shared disk and database. This state can be updated through syndication or other write operations by any of the instances at any time, immediately affecting the shared state for all other instances.
Where separate disk and separate databases are being used for each Ontoserver instance (only supported in a read-only configuration), state is synchronised differently. Each Ontoserver instance must be configured and booted with the same preload syndication feed as the other Ontoserver instances in service. Provided new instances are not enlisted to serve requests until they have successfully completed their preload operation, and write operations are not permitted, all instances will contain the same content ensuring consistent responses from the endpoint.
Content deployments for read-only endpoints
For read-only endpoints, the state the Ontoserver instances are operating on must make a step from one release state to another. To achieve this, a process similar to that described in Zero down time deployments is used, however each single instance described in that section represents the collection of Ontoserver instances at a point in time for a scaled endpoint.
That is, the process is to:
- Boot new Ontoserver instances with:
- separate state to the existing Ontoserver instances serving the endpoint. This may be:
- a new blank shared disk and new blank shared database if a shared disk and database model is being used for the Ontoserver instances
- new blank local container storage for each new Ontoserver container, and a blank database
- the same new preload syndication feed configuration
- separate state to the existing Ontoserver instances serving the endpoint. This may be:
- Wait for the new Ontoserver instances to complete preload and become ready for service
- Swap the new Ontoserver instances into service for the existing Ontoserver instances while draining connections from the existing instances.
Disposing of the state of the existing Ontoserver instances, by creating new instances with new storage/database, accounts for changes in the preload feed that may remove previously released resources. If the state is not cleared, the content of the new preload feed for the release will be added to the existing content of the instances.
Software deployments
The key point is to ensure that at any given moment the Ontoserver instances serving a single endpoint are running the same software version. If this is not the case:
- Ontoserver instances of different versions sharing disk and database (if this model is being used)may corrupt each others’ data
- The endpoint may respond differently to different requests depending upon the software version of the Ontoserver instance that the request was routed to.
To keep a consistent state of Ontoserver instance versions for active instances supporting an endpoint, new containers must be spun up and brought into service with a consistent software version. This can be done in a similar way to the process described in the section above for read-only endpoints, booting new instances and swapping them into service when they have completed their preload process.
Read/write endpoints cannot use that process, as it is designed to clear out state to replace that state with the content of a syndication feed – this would remove authors’ changes on a read/write server. Instead the state of the shared disk and database between Ontoserver instances supporting a read/write endpoint must be preserved. As a result, a short outage is required to:
- Stop all existing Ontoserver instances running the current Ontoserver version
- Boot new Ontoserver instances running the new Ontoserver version being deployed.
Note: As Ontoserver performs database schema migrations on startup, one Ontoserver instance of the new version should first be booted and allowed to completely start (completing the migration) before other Ontoserver instances are started. This is to avoid multiple Ontoserver instances attempting to concurrently upgrade the database schema.
Ontocloak
Ontocloak, as a wrapper around Keycloak, supports being run in a cluster mode to support horizontal scaling and high availability. Although it is unlikely to be needed in the context of a terminology solution, Keycloak’s documentation can be followed if this is necessary.