 Ontoserver
Ontoserver Postman
Postman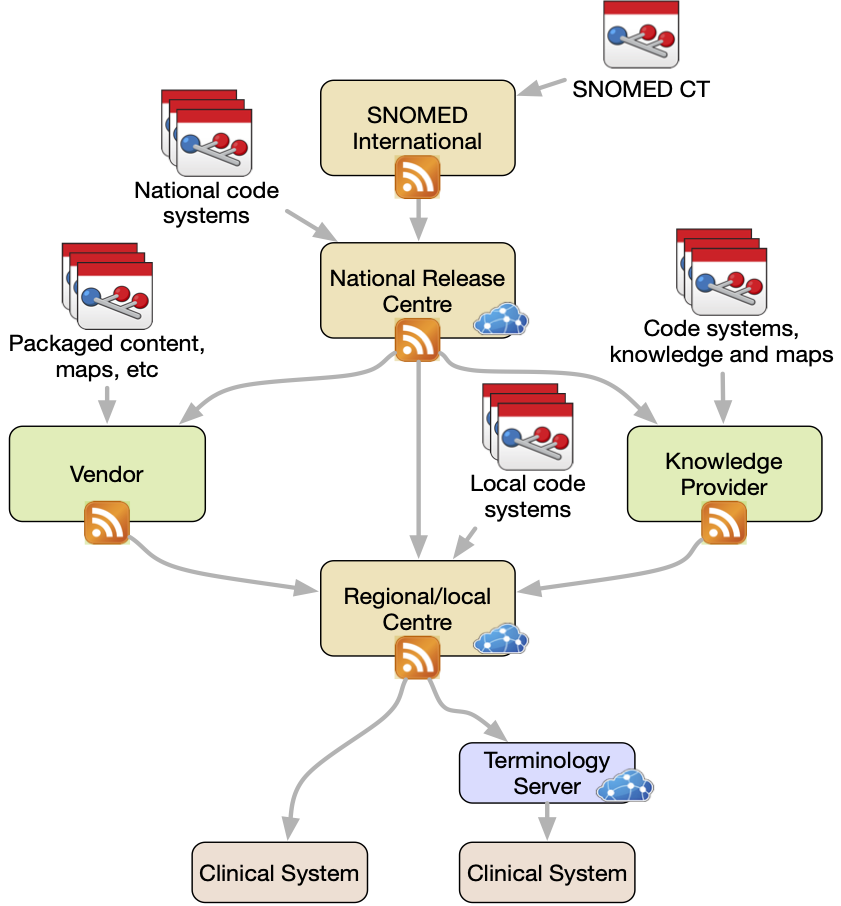
Syndication
One of Ontoserver's key features is support for content syndication.
The Syndication Interface is based on the Atom Publishing Protocol and Atom Syndication Format specifications. The NCTS Conformant Server Applications specification’s Syndication Feed section describes the elements in the feed.
In the case where a FHIR Resoure feed entry is particularly large and is known to be valid, the namespaced (xmlns:onto="http://ontoserver.csiro.au/syndication/") attribute onto:validated=true can be added to the link element along with the ncts:sha256Hash attribute and validation will be skipped when the entry is added (SHA256 validation is still performed).
Ontoserver instances can be configured to point to any number of upstream syndication feeds. Using the Syndication API, Ontoserver can then find and download supported FHIR Resource types as well as SNOMED CT and LOINC code systems.
Since Ontoserver 6.2, FHIR Packages are supported as a content type. When Ontoserver imports a FHIR Package, it imports all the supported FHIR Resources in the top-level /packagefolder that are not already present. This approach follows the intent of the FHIR package format.
Syndication Feed filtering
Sometimes it is desirable to be be able to work with a subset of an existing syndication feed. For example, just the entries for SNOMED CT.
To support this, Ontoserver understands two families of filtering parameters that may be appended as a query string to a syndication feed URL. When more than one parameter (or family) is supplied they are combined with AND: an entry is retained only if it satisfies every dimension. A feed URL with no recognised parameters is returned unchanged. Filtering never mutates the upstream feed; it produces a filtered copy.
Canonical, category and FHIR version
-
canonical
You may specify zero or more
canonicalparameters with a value following the syntax of FHIR's Canonical datatype, i.e. aurioptionally followed by|version.This filter matches entries by their
ncts:contentItemIdentifier(theuri), with the optional version qualifier governing version matching:uri(no pipe) oruri|*— matches any versionuri|(empty version) — matches only entries with no/emptyncts:contentItemVersionuri|1.0— matches only that exact version
An entry matches if it satisfies any of the supplied
canonicalvalues.For example,
?canonical=http://snomed.info/sct&canonical=http://loinc.orgwill result in a feed that contains only SNOMED CT and LOINC code system entries. -
category
You may specify zero or more
categoryparameters with a value being a string.This filter matches entries where any of the
category.termvalues of the Atom entry is equal to any of the provided parameter values.For example,
?category=FHIR_CodeSystemwill result in a feed that contains only FHIR CodeSystem resource entries.Note, legacy feed entries with a FHIR resource category term that carries a serialization-format suffix (e.g.
FHIR_CodeSystem_JSONorFHIR_CodeSystem_XML) are treated as if they just used the canonical term (FHIR_CodeSystem) for matching. -
fhirVersion
You may specify zero or more
fhirVersionparameters with a value being a string.This filter matches entries where the
ncts:fhirVersionvalue is equal to any of the provided parameter values, compared on themajor.minorcomponents only. Note that feeds generated by Ontoserver only specify the major and minor numbers of the FHIR version e.g.,4.0rather than4.0.1or4.0.2. Following the NCTS defaults, an entry with noncts:fhirVersionis treated as3.0, and an entry with an RF2-binary category is treated as4.0.For example,
?fhirVersion=4.0will result in a feed that contains only FHIR R4 (4.0.x) resource entries.
Field queries (_include / _exclude)
For finer-grained selection, Ontoserver also understands _include and _exclude field queries. Each parameter is a comma-separated list of key=value conditions:
?_include=category.name=LOINC,contentItemVersion=1.0&_exclude=published=lt2025-01-01
The following fields are supported:
| Field | Matches |
|---|---|
category.name |
an entry's category term |
category.scheme |
a category scheme |
contentItemIdentifier |
the ncts:contentItemIdentifier |
contentItemVersion |
the ncts:contentItemVersion |
fhirVersion |
the ncts:fhirVersion (NCTS-aware, compared on major.minor) |
published |
the entry's published date |
updated |
the entry's updated date |
Matching semantics:
- Within
_include, repeated string values for the same key combine with OR; different keys combine with AND. An entry is retained only if it matches every include key. - An entry is dropped if it matches any single
_excludecondition. - The overall result is “matches all includes AND no excludes”. An empty query matches every entry.
- Unknown fields and blank values are ignored.
Date fields (published, updated) accept either a bare yyyy-MM-dd date (matching the whole UTC day) or a gt/lt prefix followed by a date (strict comparison against UTC start-of-day). A range is expressed as two conditions on the same key; repeated date values for one key combine with AND:
?_include=published=gt2025-01-01,published=lt2025-02-01
Update semantics
When attempting to load an item that is identified by a canonical (the combination of a URI and version) there are some key conditions that are checked:
- If at least one Resource with the same URI and version already exists, then its
datefield is checked, and ONLY IF it is earlier than thedateof the incoming Resource then the existing Resource (with the latestdate) is updated. - Otherwise, if there are any resources with the same URI, then a NEW Resource instance is created, possibly changing the
idof the Resource, and any existing resources with the same URI are left untouched. This results in multiple resources with the same URI but different versions. - Finally, if there are no resources with the same URI, then a new Resource is created and the
idis preserved (if possible).
For items that do not have identity like this (e.g., NamingSystem), the Resource's id is used for identity and again the date field is used to determine where the existing Resource instance is updated or not.
Preload
Ontoserver also supports preload syndication feeds, where the content of one or more syndication feeds is imported when the server is started or restarted. While one use-case is to support starting with a pre-defined content-set, it is also the mechanism used to populate a read-only Ontoserver instance.
Multiple preload URLs can be specified with the atom.preload.feedLocation property, and when the preload process is triggered Ontoserver will import the union of entries in the feeds. If the instance already contains items in the feed they will be skipped.
This process may also be triggered on a running Ontoserver instance without a restart. This is particularly useful if the preload feed content has changed, so that new content can be pulled into the Ontoserver instance without interruptions.
Preload configuration details can be found here.
Scheduled preload
Preloading can be scheduled using a cron syntax to specify the schedule on the atom.preload.schedule.cron property. This is useful if a read-only Ontoserver instance is connected to a read/write Ontoserver instance using a continuous delivery model. The read-only Ontoserver instance can be configured to regularly pull newly available content from the read/write server’s syndication feed which can have content promoted to it as it becomes available.